GAN(Generative Adversarial Network): Deep Convolutional Decoding

Generative Adversarial Network model is a class of machine learning models invented by Dr. Ian Goodfellow in his PhD research in 2014. The long desire of the humans to become inventors dates back to the time of ancient Greece when they created artificial life like Pandora, Galatea and Talos!. Among humans, the generations change every 25 years. The only variable part that humans carry during these generations is their brain which keeps fueling new ideas and generating new skills in them to fulfill their desire live and grow during difficult as well as good times. However, as life shows, that desire is not ending any sooner!
Scientists understand the power of the brain which helps us crack the most difficult problems. This power multiplies when humans sit together and collaborate with each other for problem solving. This interesting fact about brain development gave the creative minds a perfect reason to create an invention to function the same way as the human brain interacts and solves problems. This information exchange phenomenon is the most important aspect of our learning process.
Gone are the days when Game theory was very well known to only Mathematicians, Biologists, Economists and all those economic agents who were using it to generate Nash equilibrium strategies in interaction games. Everyone is on the run to automate tasks using Machine learning development. Combining ideas from game theory to work with machine learning is a new advancement for inventors and it is on this point of the growth line of human society that we can start explaining our core topic.
In the 1950’s, when Alan Turing came up with the idea of Imitation game theory then it was the first thinking attempt by mankind to create human level machines with practice in all domains of our world. Since then we are still manufacturing such holy grail machines which can really do the same thing. In a nutshell, a very big step towards this idea is the Generative Adversarial Network models described by Yann LeCun as “Coolest idea in deep learning in last two decades”. If you have read other articles on GAN’s then you will know that this article is different from others just because of its simplicity. We will go through the Deep Convolutional GAN model procedure and model evaluation parameters which makes it a far better version than the first version of GAN model.
What is a GAN Model?
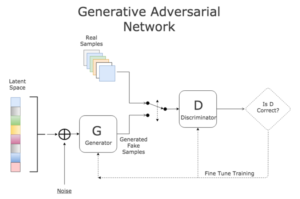
In this model, given a training set, two neural networks (Generator and Discriminator) contest with each other. Discriminator differentiates real and fake data while Generator produces fake examples as a substitute for real data and tries to cheat Discriminator with that produced fake data. Discriminator is trained on a training dataset and Generator is trained on Discriminator’s ability to classify real and fake examples.
Both networks iterate the process and iteration can be increased or decreased on the basis of discriminator’s ability to minimize the loss. The process ends when the generator produces fake images as a perfect substitute for real images. This achievement point in the whole process is called Nash Equilibrium which is used in game theory for the very best available solution of a game. This is the very core idea of GAN modelling.
Source: https://medium.com/machinelearningadvantage/create-any-image-with-c-and-a-generative-adversarial-network-6031a4b90dec
In the above part, we understood how the GAN model works. But these models were having
difficulties in practice due to instability in training and implementations of GAN networks. One idea to solve this instability issue was implementing a separately trained Convolutional network at each level with all iterations, popularly known as Laplacian Pyramid GAN. It significantly increases model performance. But it was found to be computationally very expensive and complex. Imagine what we can do with a more powerful network architecture. One more idea that was put to practice was, instead of implementing the above two layers of feed forward network with Laplacian method, using the above generator and discriminator with Convolutional neural network, popularly known as Deep Convolutional Generative adversarial network or DCGAN.
What is the DCGAN Model?
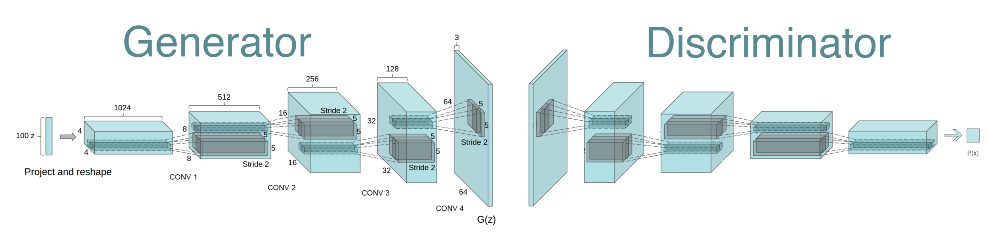
DCGAN Model was introduced in 2016 by Alec Redford, Soumith Chintala and Luke Metz. They successfully incorporated Convolutional networks directly into a full fledged GAN model. To understand the architecture of DCGAN, one must understand three core concepts of DCGAN, viz:
- GAN
- Convolutional filters
- Batch Normalization
As we have already discussed GAN in a detailed manner, let’s fine tune your understanding.
1. Generative Adversarial Network
Train the Generator: Take a batch of noisy data from latent space (randomly chosen data) and generate a batch of fake examples. After feeding these example data to the discriminator, compute classification loss for the same and then back propagate the loss to update generator model parameters to maximize the classification loss of Discriminator.
Train the Discriminator: Compare a batch of real example dataset with random noisy dataset fed by the Generator. Compute the classification loss for discriminator and use this loss to update the model parameter to minimize the classification loss.
As the iteration is sequential in nature, they are training each other to perform better and the process ends when the generator will produce exactly the same images as real ones. This is how GAN modelling works.
2. Convolutional filters:
In the above explanation, we can easily observe that neural networks are connected in flat and fully connected layers. To enhance the process building, one may argue that these flat layers can be arranged in three dimensions as width, depth and height. Hence, this will produce three dimensional layers output. Generative Adversarial Networks belong to the set of generative models.
3. Batch Normalization:
Normalization is scaling all the dataset so that after scaling it has zero mean and unit variance. So Batch Normalization is normalizing the inputs to each layer, and for each training batch as it iterates through the network layer. It comes with many advantages since it becomes very easy to compare very different scale datasets after normalization and the process of training becomes less sensitive to scaled parameters. For a batch normalization, some adjustments are made as compared to basic normalization.
GAN can create images that look like photographs of human faces, even though the faces don’t belong to any real person. Many things may not be clear for you. Don’t worry. Once we implement the above core DCGAN parameters, these concepts will surely become clear. Now, lets implement DCGAN in Google Colaboratory:
The example below is from the very famous book GAN in Action: Deep Learning with Adversarial Network by Jakub Langr and Vladimir Bok. We are going to use MNIST Dataset from the KERAS Library of Python to generate handwritten digits by using the DCGAN Model-
putting all steps together to implement DCGAN:
First import all required packages:
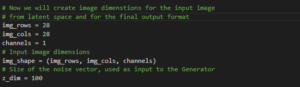
Now we will create image dimensions for the all training and final output size:
To implement the Generator, we follow the steps below:
- Take a random noise vector and reshape it into a 7 × 7 × 256 tensor through a fully connected layer.
- Use transposed convolution, transforming the 7 × 7 × 256 tensor into a 14 × 14 × 128 tensor. (tensor is multi-dimensional matrix)
- Apply batch normalization and the Leaky ReLU activation function.
- Use transposed convolution, transforming the 14 × 14 × 128 tensor into a 14 × 14 × 64 tensor.
Notice that the width and height dimensions remain unchanged. This is accomplished by setting the stride parameter in Conv2DTranspose to 1.
- Apply batch normalization and the Leaky ReLU activation function.
- Use transposed convolution, transforming the 14 × 14 × 64 tensor into the output image size, 28 × 28 × 1.
- Apply the tanh activation function.
After each transposed convolution layer, we apply batch normalization and the Leaky ReLU activation function. At the final layer, we do not apply batch normalization and, instead of ReLU, we use the tanh activation function.
- GAN are an architecture for automatically training a generative model by treating the unsupervised problem as supervised and using both a generative and a discriminative model.
The codes with respect to above explanation are as follows:
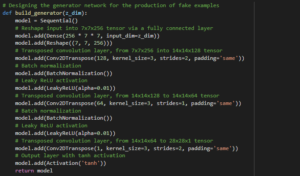
- GAN provide a path to sophisticated domain-specific data augmentation and a solution to problems that require a generative solution, such as image-to-image translation.
In a similar manner, we will also create Discriminator network with the help of Convolutional network and also process batch normalization as described above with the activation function as sigmoid function layer.
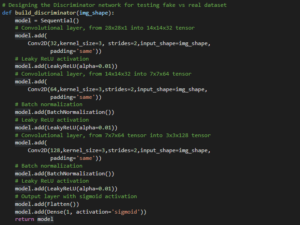
Now its the time to design DCGAN model with the help of Discriminator and Generator network:
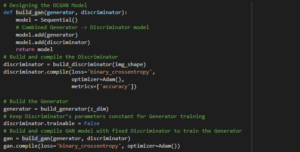
As we can observe in the code above that we choose optimizer as Adam() as Adam keeps an exponentially decaying average of past gradients. You can opt for other optimizers from the family of deep learning optimizers also.
After designing the model, we need to train the very famous MNIST Dataset from KERAS library of python.
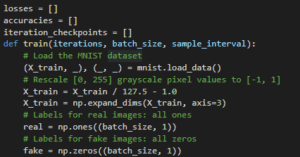
During the designing training process, we are setting up hyperparameters as losses, accuracies, iterations and batch size. This is to ensure that our model adapts these parameters and reaches the desired outcomes.
Inside the train function designing itself, we also set up training dataset for discriminator and also rely on random normal distribution to generate fake images through Generator for the initialization of iteration. After initialization of fake images, we rely on hyperparameters to tune the rest of the task.
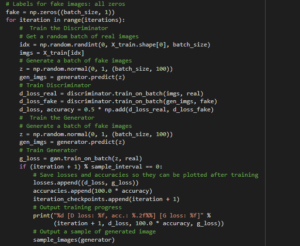
Now it’s time to design the output images’ size and dimensions on the black and black colored grids:
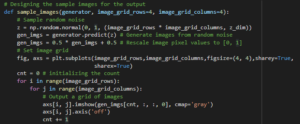
The final step is to define the hyperparameters as number of iterations, batch size and of course, sample size for each and every iteration and hence command our desired trained model.
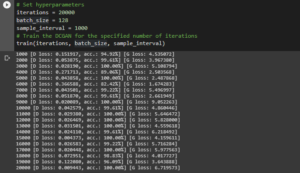
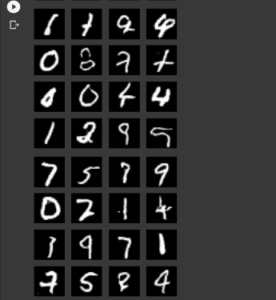
GANs are an exciting and rapidly changing field. So when all the above iterations take place, you can keenly observe the accuracy fight between Discriminator and Generator network as Discriminator tries to minimize its loss and Generator tries to maximize Discriminator loss. In my trial iteration, we achieved very good accuracy as can be shown above in the last 20th batch of sample intervals. Your outcomes may differ because of first time input random values as fake data for the Generator.
Run your iterations and see the quality of produced images using the DCGAN model. Enjoy!
Similar Articles
-

AI is Revolutionizing the Gaming Industry 10-14-2025
Ever been outsmarted by a clever enemy in a video game, or wondered how a…
-

ACES COLOR SPACE IN VISUAL EFFECTS 10-10-2025
ACES, which stands for the Academy Color Encoding System, is a standardized color management system…
-

The Future of 3D Game Art (2025): Trends, Tools & New Roles Every Studio Needs 09-23-2025
Game art is no longer just “model, texture, animate.” With real-time engines (UE5/modern Unity), procedural…
-

Ignite Your Ink: Why You Should Be Part of Inktober 2025 09-17-2025
Hey budding artists ? Every year, artists around the world challenge themselves to draw one…